Golang: The time complexity of append()

In Go, append(slice, x) is one of the most used built-in functions. But have you ever thought about a simple question: what is the time complexity of it?
The short answer: The amortized cost of append() is O(1), but the worst-case cost is O(N).
Before I move to the long answer, I'd like to add a disclaimer first: The Go Programming Language Specification is supposed to be a single source of truth. Everything else can be treated as implementation details, which may or may not be consistent across versions, platforms, and compilers. What I'm writing here is all about those implementation details. I'm using the version of go1.12.4 darwin/amd64 with the origin compiler gc.
What happens when we call append()
The compiler's code steps in first. It rewrites append(src, a) to something like the following:
func() {
s := src
if cap(s) --- len(s) < 1 {
s = growslice(s, len(s)+1)
}
n := len(s)
s = s[:n+1]
s[n] = a
return s
}
The compiler will do things slightly differently if we call append(s1, s2...) or append(s1, make([]T, l2)...), please refer to the detailed code¹ if you are interested. growslice() here is a function that is in Golang's runtime package.
growslice() essentially carries out the following actions²:
- Calculate the new cap of the slice after growing:
- For slices with
len<1024, it will doublecap; -
For slices with
len>= 1024, newcapwill be (1.25 *cap); (note the difference oflenandcapof a slice³)
- For slices with
- Determine the memory size of the new slice.
- Call
mallocgc()to allocate memory for the new slice, and conditionally callmemclrNoHeapPointers()to clear some memory. - Call
memmove()- a function written in assembly language - to copy the data from the old memory address to the new memory address.
At first glance, I thought memmove() was where the O(N) time complexity was coming from, but after I looked into the CPU profiling of append() I found this was not true.
CPU Profiling of append()
I created a simple main.go, where Append() will build up a slice with 1024 elements.
package main
const size = 1<<10
func Append() {
var s []int
for i := 0; i < size; i++ {
s = append(s, i)
}
_ = s
}
And a simple main_test.go:
package main
import "testing"
func BenchmarkAppend(b *testing.B) {
for n := 0; n < b.N; n++ {
Append()
}
}
Go provides some tools for profiling CPU usage, but I like prefer the handy UI that Goland has:
After analyzing the CPU profiles from multiple runs, I found out two facts. First, growslice() always takes more than 90% of CPU time in building up the slice, which is what we expected. Second, memmove() is never the most time-consuming part of growslice() when the size of the slice is not huge.
Look at these two screenshots of CPU profiles:
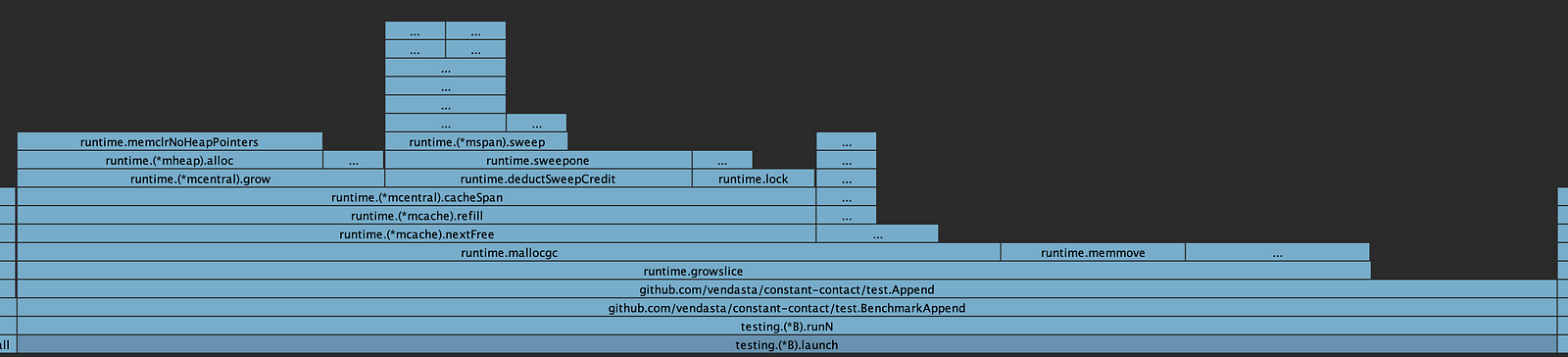

We can see that allocating memory for the growing slice (function mallocgc()) takes the majority of CPU time. The more interesting thing is that memmove() can take 0 CPU time in some cases (see the second screenshot). I'll dig deeper into that when possible.
We can play with the size and see that memmove() will spend a more significant part of the CPU time as size grows. Running the benchmark with size = 1 << 20 ends up with the following CPU profile, where memmove() takes 80% of the CPU time in growslice().

How about allocating the slice size beforehand?
We can see that append() is probably not the most performant way of building a slice. If we know the size of a slice beforehand, we want to use make() to create the slice with the known capacity (cap). But compared to append(), how much better will it be? Let's run some more benchmarks to see.
Now, main.go looks like this:
package main
var size = 1 << 10
func Append() {
var s []int
for i := 0; i < size; i++ {
s = append(s, i)
}
_ = s
}
func Make() {
s := make([]int, size)
for i := 0; i < size; i++ {
s[i] = i
}
_ = s
}
And main_test.go becomes:
package main
import "testing"
func BenchmarkAppend(b *testing.B) {
for n := 0; n < b.N; n++ {
Append()
}
}
func BenchmarkMake(b *testing.B) {
for n := 0; n < b.N; n++ {
Make()
}
}
Running the benchmark with go test -bench=. gives us the following result:
BenchmarkAppend-8 500000 3584 ns/op
BenchmarkMake-8 1000000 1586 ns/op
From the result, we can see that, in the case of size = 1024, if we can create the slice with a capacity, we can save more than 55% CPU time on creating and populating data into the slice.
And if size = 1 << 20, the result will be more significant:
BenchmarkAppend-8 300 5911366 ns/op
BenchmarkMake-8 1000 1209488 ns/op
Takeaways
append()can be expensive, although its amortized cost is O(1) in theory.- When the size of a slice is small, allocating memory can be the most time-consuming part in populating the slice; when the size grows, moving data in memory will occupy more CPU time.
- If we can know the size of a slice, we should use
make()to create the slice instead of dynamically appending to it.
All of these may seem to be very simple, but I enjoyed the process of measuring and proving them. Hope you enjoyed it too!
Appendix: References
[1]: The compiler rewrites append() operator: gc/walk.go
[2]: growslice() in runtime package: runtime/slice.go
[3]: len is how many items are in the slice. cap is the total capacity of the slice. len will always be less than or equal to cap.
An interface in Go with a nil value isn't nil unless both its type and value are nil.
Newer PostHow To Mock DNS Server in JavaExploring dnsjava's retry logic by creating a mock DNS server in Java, highlighting the importance of testing third-party libraries to fully understand its behaviour.